
¿Qué es la ciencia de datos?
Juan S. Mármol Yahya
Chief Data Scientist
Business Data Evolution
Julio 2016
Resumen ejecutivo
Hoy las empresas tienen la oportunidad de extraer conocimiento a partir de grandes volúmenes de información generadas de forma interna o externa, procesándola utilizando métodos estadísticos y de inteligencia artificial en conjunto con un gran poder de computo paralelo y distribuido. Muchas de las empresas o entidades públicas y privadas que han utilizado a la ciencia de datos han obtenido grandes beneficios, llegando algunas a tener crecimientos exponenciales. En este artículo explicamos qué es la ciencia de datos, cuál es el proceso de obtención de conocimiento, el perfil de los equipos que lo realizan y algunos casos de éxito. Todo Comienza con una pregunta.
Ciencia de datos
Durante los últimos años hemos sido testigos de cómo la tecnología avanza a pasos agigantados. Cada vez es más claro que los avances que antes percibíamos como lineales son realmente exponenciales. Esto es verdad no sólo en el ámbito de la electrónica, en donde, hasta el momento, cada dos años se duplica el número de transistores dentro de un microprocesador (Templeton, 2015). Todo lo que se digitaliza evoluciona de esta manera (Kurzweil, 2001). El 90% de la información que existe en el mundo se ha producido en los últimos dos años y esto sólo es el comienzo. Se espera que los negocios creen 44 veces más información para el año 2020 que lo que hacían en el 2009. Pero los datos pertenecientes a las compañías sólo son una parte minúscula del universo total. Más de 3 billones de personas están en línea cada día, generando y compartiendo información. Facebook tiene 1,090 millones de usuarios que envían en promedio 31.25 millones de mensajes y ven 2.77 millones de videos cada minuto. 100 horas de videos se suben a YouTube cada minuto y se envían aproximadamente 500 millones de tweets cada día. La estadística más preocupante es que sólo el 0.5% de la información se usa y analiza (Marr, 2015) (Lett, 2016). ¿Cómo podemos aprovechar esta cantidad tan grande de información? Hoy las empresas tienen la oportunidad de utilizar métodos estadísticos y de inteligencia artificial en conjunto con gran poder de cómputo para explotar de mejor manera toda esta información.
Inicialmente se utilizaban con el fin de hacer más eficiente la operación diaria. Conforme fuimos capaces de recopilar estos datos y hacerlos accesibles en cualquier momento que se requiriera, se comenzó a obtener información valiosa. Ya no se toman decisiones con base en el instinto y se comenzó a tomarlas con base en hechos. Se pudo responder con certeza la pregunta ¿qué fue lo que pasó? El siguiente paso es obtener conocimiento de la información y poder responder preguntas tales como ¿por qué pasó?,¿cuándo volverá a pasar? y, finalmente, ¿cómo podemos hacer que ocurra? (Gartner, 2012) La Ciencia de Datos es la disciplina que nos permite contestarlas.
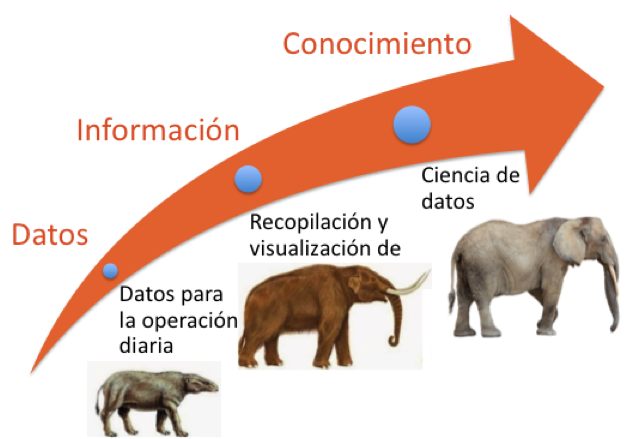
Antes que todo, es importante entender que el énfasis es en la palabra Ciencia y no en Datos. Hay disciplinas, como Big Data, que se enfocan en hacer posible que podemos almacenar, acceder y procesar grandes volúmenes de información (Laney, 2012). Ciencia de Datos está enfocada en la obtención de conocimiento proveniente de datos estructurados y/o no estructurados. Además, permite la creación de productos de datos: una aplicación que adquiere su valor a partir de datos, y crea más datos como resultado. No es sólo una aplicación con datos; es un producto de datos. No es de sorprender que, en esta disciplina, como en el método científico, todo comienza con una pregunta.
 |
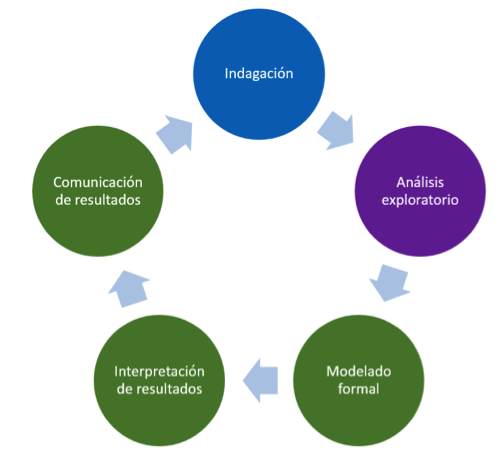 |
Método Científico (Edmund, 1984) |
Proceso de obtención del conocimiento |
Todo comienza con una pregunta
La primera fase, y más importante, es en la que nos planteamos la pregunta que queremos contestar. Determinamos qué es lo que queremos conocer sobre los datos. Es muy relevante que la pregunta esté correctamente planteada, pues esta dirigirá el resto del estudio. Hay diversos tipos de preguntas y dependiendo el tipo se determina la metodología mediante la cual se responderá. Las preguntas pueden ser: descriptivas, exploratorias, deductivas, causales, predictivas y mecanicistas.
Descriptiva |
Exploratoria |
|
Recolecta, presenta y caracteriza un conjunto de datos
Ejemplo: ¿Cuál es el perfil de nuestros mejores clientes? |
Investigación realizada para ganar familiaridad con un fenómeno
Ejemplo: ¿Es positiva la opinión de nuestros clientes en redes sociales del nuevo producto que lanzamos? |
Predictiva |
Causal |
|
Análisis de hechos actuales o pasados con el fin de predecir eventos futuros desconocidos
Ejemplo: ¿Qué producto debo ofrecer a cada cliente para incrementar la probabilidad de compra un 20%? |
Determinar las causas detrás de un evento
Ejemplo: ¿Por qué estamos perdiendo clientes en la Ciudad de México? |
Deductiva |
Mecanicista |
|
Inferir a partir de una muestra aleatoria el comportamiento de la población.
Ejemplo: ¿Cuál es el nivel de ingresos de mis clientes? |
Comprender los mecanismos detrás de un proceso
¿Existe un proceso mediante el cual perdemos a nuestros mejores clientes? |
La pregunta debe contestar de manera adecuada la verdadera necesidad del negocio. Por ello es importante que la pregunta tenga una métrica asociada para acotarla; que no mencione alguna metodología de análisis en particular para su resolución; indique tiempos; y se ligue a una unidad de negocio o departamento en particular.
Una vez que se tiene definida la pregunta, se deben obtener los datos necesarios para responderla. Puede darse el caso que se cuente con toda la información necesaria, pero varias veces se requerirá realizar un esfuerzo adicional para conseguirla.
En la segunda fase se realiza el análisis exploratorio. En esta etapa se determina si con los datos que contamos podemos responder o no a la pregunta. Para ello, se realiza un análisis previo de la calidad de la información, se limpian los datos lo más posible, identificando y corrigiendo datos, incorrectos, incompletos, inexactos, no pertinentes, atípicos, etc. Una vez limpios los datos se obtiene el análisis descriptivo de cada uno de los campos relevantes (distribuciones de frecuencias, medidas de tendencia central y medidas de dispersión) y, si se requiere, análisis de correlación.
Culminados estos análisis, se esboza el primer bosquejo de la solución. No tiene que utilizarse necesariamente ningún método de modelado formal, ni ninguna prueba estadística. Simplemente esto es para darse una idea de cómo podría ser la respuesta.
En algunas ocasiones el resultado de esta etapa nos indicará que no contamos con los datos necesarios para resolver la pregunta, o simplemente sí contamos con ellos, pero están sumamente distorsionados como para poder llegar a una conclusión sin incertidumbre. A pesar de que esto puede verse como fracaso, realmente es un hallazgo importante, ya que nos permitirá no perder tiempo ni dinero en seguir buscando un modelo adecuado y describir los pasos que se deben seguir para sí contar con ellos a corto o mediano plazo.
La tercera fase la dividimos en tres etapas: Modelado formal; interpretación de los resultados y comunicación de los resultados.
En el modelado formal, definimos que parámetros estamos tratando de estimar para contestar la pregunta que nos planteamos, utilizando el bosquejo generado en la fase anterior. Dependiendo de la pregunta que se quiere responder, se siguen distintas metodologías. Por ejemplo, la inferencia estadística nos ayuda a obtener conclusiones sobre una población a partir de una muestra; las regresiones nos permiten predecir resultados cuantitativos a partir de ciertas variables dadas; y las herramientas de aprendizaje de máquina, provenientes del área de inteligencia artificial, predecir, agrupar, aprender y detectar patrones.
Podemos categorizar las herramientas de aprendizaje de máquina por la forma en que “aprenden”. Las supervisadas, utilizan valores históricos de la variable que se quiere predecir, o se les proporciona un criterio de éxito o fracaso de la predicción. Ejemplos de estas son las redes neuronales, las máquinas de soporte vectorial, los árboles de decisión y los bosques aleatorios. En las no supervisadas, se detectan patrones sin tener variables o criterios objetivo. Ejemplo de estas son K-Medias, redes de Kohonen, análisis de componentes principales y análisis de factores. Al proceso mediante el cual “aprenden” estas herramientas se le conoce como entrenamiento y es computacionalmente intensivo. Dado que normalmente estaremos trabajando con grandes volúmenes de información, muchas veces requeriremos de cómputo paralelo y distribuido, a través de varias decenas y hasta cientos de servidores, para obtener resultados en un tiempo razonable.

Esquema en capas de una red neuronal
Debemos definir, a partir del análisis exploratorio y la experiencia, las variables que se utilizarán en las distintas herramientas de modelado. Es importante crear nuevas variables a partir de las originales para enfatizar las características que son relevantes para resolver la pregunta que nos planteamos.
Muchas veces un solo modelo no basta, por lo que es necesario probar y mezclar distintas herramientas para obtener el resultado esperado. Esto se hace utilizando una metodología que nos permite calificar los resultados, examinando la sensibilidad del modelo a distintos escenarios. Esto es importante para asegurarnos de obtener evidencia suficiente de que nuestra respuesta es correcta dentro de los parámetros definidos.
El reporte técnico que se entrega debe incluir el modelo, para asegurarse que los resultados sean reproducibles como lo dicta el método científico.
Cuando tenemos el modelo final, interpretamos los resultados, poniendo énfasis en determinar si la respuesta se adecua a lo que originalmente se esperaba o estamos encontrando algo completamente distinto y revelador. Determinamos cual es el nivel de certeza que tenemos de los hallazgos obtenidos y cuáles son sus implicaciones.
Finalmente se realizan presentaciones de los resultados a la audiencia interesada, y se determinan las siguientes acciones a realizarse y las nuevas preguntas que surgen del análisis que deben ser investigadas y respondidas. El ciclo comienza de nuevo.
Como lo mencionamos anteriormente, los parámetros del modelo se obtienen utilizando datos históricos, por lo que, si evoluciona el negocio y la conducta de los clientes, se requerirá una calibración periódica del mismo.
¿Quiénes se pueden beneficiar de la ciencia de datos?
Cualquier empresa o entidad pública o privada que cuente con información, sea estructurada o no estructurada, y tenga una pregunta relevante para su futuro cercano, puede beneficiarse con la ciencia de datos. De hecho, se puede utilizar como una eficaz herramienta competitiva en múltiples escenarios.
Las siguientes empresas y entidades han utilizado exitosamente la ciencia de datos:
Banco de Inglaterra
La excelencia en la analítica de datos es uno de los pilares estratégicos del Banco Central de Inglaterra. Han hecho uso creativo de las mejores herramientas analíticas y fuentes de datos para hacer frente a los problemas más desafiantes y relevantes que han tenido. Fueron los primeros en crear el puesto de “Chief Data Officer”. Este equipo logró resolver el gran reto de consolidar la información proveniente de diversas áreas de la institución y explotarlo adecuadamente.
Gracias a esto, han desarrollado modelos como el del comportamiento del mercado de la vivienda, que combina datos granulares (es decir, datos agregados geográficamente sobre los préstamos individuales) con datos de política macroeconómica, con el cual se mitiga de manera importante que ocurra otra crisis como la de 2008. La ciencia de datos ayuda a la transparencia en la determinación de políticas y en la toma de decisiones.
Internamente utilizaron información no estructurada contenida en correo electrónicos para evaluar la comunicación que existía entre las distintas áreas del banco y con ello poder tomar acciones correctivas para mejorarla. Además, han utilizado mensajes de Twitter para determinar signos de posibles fugas en bancos escoceses previo a la votación que determinaría si Escocia abandonaría o no al Reino Unido. (Fitzgerald, 2016)
Campaña de Barack Obama 2012
Durante la campaña para la elección presidencial de Estados Unidos del 2012, Barack Obama contrató a Rayid Ghani, un experto en ciencia de datos y lo nombró científico en jefe de la campaña. Consolidaron información de los votantes, obtenida de múltiples fuentes, con la información en redes sociales, mercadotecnia y otras fuentes. Su objetivo era predecir cuatro variables para cada individuo: ¿qué tan favorable era su opinión de Barack Obama? ¿qué tan probable era que fuera a votar?, ¿qué tan bien respondería a un recordatorio a salir a votar? y por último ¿qué tan posible es que cambiara su voto basado en una conversación de un tema en particular? Basado en estos modelos, corrían 66,000 simulaciones cada noche y los resultados eran entregados y utilizados por los equipos de voluntarios en la campaña, que decidían con esta información a quién llamar, qué casa visitar y qué decir. (Domingos, 2015)
Walmart
Walmart recopila 2.5 Petabytes de datos no estructurados provenientes de 1 millón de clientes en el mundo cada hora. Esto es equivalente a 167 veces los libros de la Biblioteca del Congreso de Estados Unidos. Para explotarlos utiliza diversas metodologías de minería de datos y aprendizaje de máquina. Mediante ellas, identifican patrones que se pueden utilizar para proporcionar recomendaciones de productos a los clientes. Con esto han aumentado su tasa de conversión de ventas. Por ejemplo, Se detectó que las ventas de Pop-tarts de fresa aumentaban 7 veces en las zonas donde existía una alerta de huracán. Desde entonces coloca todas las Pop-tarts de fresa que tienen en las cajas registradoras en los días previos a un huracán.
Los laboratorios de análisis de Walmart revisan cada clic que se hace en Walmart.com; lo que los consumidores compran en las tiendas y en línea; lo que está en tendencia en Twitter; miles de millones de mensajes de Facebook; videos de Youtube; publicaciones en blogs; eventos locales, tales como cuando los Gigantes de San Francisco ganaron la Serie Mundial; la forma en que cambios climáticos afectan los patrones de compra; y mucho más. Todo esto con el fin de encontrar hallazgos que permitan a los clientes disfrutar de una experiencia de compra personalizada. Es así que está contactando a sus clientes y a los amigos de los clientes que envían un Tweet o mencionan algo acerca de sus productos para darles mayor información sobre ellos y proporcionarles algún descuento especial. (DeZyre.com, 2015)
AirBnB
AirBnB es una de las compañías de economía colaborativa de más rápido crecimiento de reciente puesta en marcha. A la cadena Hilton le tomó 94 años construir 758,502 cuartos en 100 países (Mudallal, 2015). AirBnB ha logrado poner a disposición de sus clientes en sólo 6 años más de 1,000,000 cuartos en 192 países. Cuentan con 25 millones de usuarios y generan 20 Terabytes de información al día. El secreto detrás del crecimiento del negocio está en cultivar la confianza. La ciencia de datos es el núcleo en la detección de los factores de confianza para involucrar a más usuarios y descubrir nuevas maneras de cómo aumentar la confianza.
Es por ello fundamental que sus algoritmos encuentren parejas de huéspedes y anfitriones para lograr experiencias inigualables. Se utiliza la interacción entre ellos; los eventos actuales; y la historia del mercado local para ofrecer recomendaciones en tiempo real que los viajeros pueden aceptar o rechazar.
Mediante análisis de regresión han encontrado que la calidad de las imágenes juega un papel vital en las reservaciones. Para mejorar la calidad de las imágenes comenzaron a proporcionar fotografía profesional gratuita para los anfitriones y los resultados fueron sorprendentes. Ahora AirBnB realiza reconocimiento y análisis de las fotos de las propiedades de los anfitriones, mediante algoritmos de aprendizaje de máquina, para averiguar cuáles funcionan mejor, qué características las hacen las más buscadas y de qué tipo son las que obtienen el mayor número de clicks. Se espera que el algoritmo recomiende automáticamente el servicio de fotografía profesional gratuito, conectando anfitriones con fotógrafos profesionales cercanos. (DeZyre.com, 2016)
Equipo de ciencia de datos
El equipo que se necesita para resolver este tipo de problemas es altamente especializado. En términos generales, existen tres roles en un proyecto de ciencia de datos: el científico de datos, el arquitecto de datos y el ingeniero de software.
- El científico de datos, encargado de los análisis descriptivos, del modelado y de la interpretación de los resultados, puede ser un matemático con especialidad en la estadística o bien un especialista en aprendizaje de máquina. Formación típica: Licenciados en Matemáticas Aplicadas, Matemáticas y Computación, Actuarios, Maestros en Ciencias de Datos, en Ciencias en Computación, con conocimiento de estadística descriptiva, inferencia, modelos predictivos, diseño experimental, uso de mineros de datos, inteligencia artificial, aprendizaje de máquina, lenguajes tales como SQL, Python, R, Julia y SAS.
- El arquitecto de datos tiene como funciones obtener la información necesaria; diseñar las bases de datos que se requieran para almacenarla; extraerla y pre procesarla agrupándola como se requiera; y, en conjunto con el científico de datos, limpiarla. Formación típica: Ingenieros y Licenciados en Computación, con conocimiento de administración de bases de datos estructuradas y no estructuradas utilizando manejadores como MySQL, Hadoop y Spark; conocimiento de fuentes secundarias de información tales como INEGI, Facebook, Twitter, etc.; y uso de lenguajes como SQL, Python y para la explotación de las bases y la limpieza de los datos.
- Por último, el ingeniero de software diseña y desarrolla los programas necesarios para implementar las soluciones a través de aplicaciones y/o páginas web; y colabora de manera cercana con los clientes para la integración de estas aplicaciones en sus sistemas. Formación típica: Ingenieros y Licenciados en Computación, con conocimientos en Ingeniería de Software; desarrollo de aplicaciones web, móvil e interfaces con sistemas legados; y lenguajes como C, Java, Swift, Groovy, HTML y PHP.
Servicios de ciencia de datos
En la actualidad existen muchas aplicaciones genéricas que prometen obtener resultados rápidos sin la necesidad de contar con un equipo de ciencia de datos. Sin embargo, dada la cantidad de posibles escenarios y herramientas de modelado que pueden utilizarse, es altamente improbable que se amolde 100% a las necesidades específicas de cada tipo de pregunta y de cada tipo de empresa. Además, si buscamos explotar nuestra información como diferenciador y utilizamos la misma herramienta que nuestra competencia, ¿en que nos estamos diferenciando realmente?
Dado que el nivel de especialización que se requiere en los equipos de ciencia de datos es muy alto, sus costos son de igual forma muy altos. Esto sin contar la infraestructura tecnológica que se requiere (mineros de datos, programas para el análisis estadístico y servidores para procesar la información) que de igual forma es sumamente costosa. Es por ello que contratar a un equipo que dé servicios de ciencia de datos es una opción atractiva y viable para obtener soluciones a la medida. La inversión es fácilmente escalable a través de proyectos cortos con resultados inmediatos. Todo esto sin descuidar la misión y visión de la compañía.
La confidencialidad de tus datos es algo fundamental. Es por ello que la empresa que otorga el servicio de ciencia de datos debe contar con experiencia en el manejo de la información de terceros, además de proporcionar mecanismos que aseguren la confidencialidad de la misma, como uso de datos anónimo (sin nombres, ni ningún dato sensible); mecanismos de encriptación en el traslado y almacenamiento de la información; sistemas de cómputo protegidos contra ataques externos y, en caso de que se requiera, que ni el científico de datos conozca la empresa a la que pertenecen los datos.
Además, quien otorgue el servicio de datos debe ser capaz de realizar su trabajo on premise, utilizando la infraestructura de las empresas que los contraten; en sus oficinas, utilizando la infraestructura con la que cuenten; en la nube de preferencia de las empresas; o una mezcla de estas alternativas.
Business Data Evolution
En Business Data Evolution cumplimos con todas las características mencionadas en este artículo. Contamos con personal altamente calificado, con estudios y certificados de las mejores universidades de los Estados Unidos y con más de diez años de experiencia en ciencia de datos. Además, contamos con varias décadas de experiencia en el manejo de información confidencial, proveniente de nuestra empresa hermana Digital Data.
Y recuerda… todo comienza con una pregunta.
Bibliografía
DeZyre.com. (2015-23-5). How Big Data Analysis helped increase Walmart’s Sales turnover? Retrieved 2016-15-6 from DeZyre.com: https://www.dezyre.com/article/how-big-data-analysis-helped-increase-walmart-s-sales-turnover/109
DeZyre.com. (2016-25-1). How Data Science increased AirBnB's valuation to $25.5 bn? Retrieved 2016-15-6 from DeZyre.com: https://www.dezyre.com/article/how-data-science-increased-airbnbs-valuation-to-25-5-bn/199
Domingos, P. (2015). The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our World. New York: Basic Books.
Edmund, N. W. (1994-3-6). The General Pattern of the Scientific Method (SM-14). The General Pattern of the Scientific Method (SM-14)., Fl, USA: Edmund Scientific Co. Retrieved 2016-14-6 from Wikipedia: https://es.wikipedia.org/wiki/Método_cient%C3%ADfico
Fitzgerald, M. (2016). Better Data Brings a Renewal at the Bank of England . MITSloan Management Review, 3-11.
García, V. G. (2010). Estimación y clasificación de daños en materiales utilizando modelos AR y redes neuronales para la evaluación no destructiva con ultrasonidos. Universidad de Granada, Teoría de la Señal, Telemática y Comunicaciones. Granada: Universidad de Granada.
Gartner. (2012-12-12). Gartner Pictures. Retrieved 2016-14-6 from Flickr.com: https://www.flickr.com/photos/27772229@N07/8267855748
Kurzweil, R. (2001-7-3). The Law of Accelerating Returns. Retrieved 2016-14-6 from Kurzweil accelerating intelligence: http://www.kurzweilai.net/the-law-of-accelerating-returns
Laney, D. (2012-12-12). Information Economics, Big Data and the Art of the Possible with Analytics. Retrieved 2016-14-6 from ibm.com: https://www-01.ibm.com/events/wwe/grp/grp037.nsf/vLookupPDFs/Gartner_Doug-%20Analytics/$file/Gartner_Doug-%20Analytics.pdf
Lett, E. (2016-13-1). Infographic: What Is Big Data? Retrieved 2016 14-6 from Balckvard.com: http://www.blackvard.com/what-is-big-data/
Marr, B. (2015-30-9). Big Data: 20 Mind-Boggling Facts Everyone Must Read. Retrieved 2016-14-6 from Forbes / Tech: http://www.forbes.com/sites/bernardmarr/2015/09/30/big-data-20-mind-boggling-facts-everyone-must-read/#455f2b096c1d
Mudallal, Z. (2015-20-1). Airbnb will soon be booking more rooms than the world’s largest hotel chains. Retrieved 2016-15-6 from Quartz: http://qz.com/329735/airbnb-will-soon-be-booking-more-rooms-than-the-worlds-largest-hotel-chains/
Templeton, G. (2015-29-7). What is Moore’s Law? Retrieved 2016-14-6 from Extremetech.com: http://www.extremetech.com/extreme/210872-extremetech-explains-what-is-moores-law